
In-Memory Data Grid
In-Memory Data Grid (IMDG)란 대용량 데이터를 메모리에 저장하고 처리하기 위한 분산 캐싱 소프트웨어 기술이다.
IMDG 는 다수의 물리 서버를 연결하여 클러스터를 형성하고, 이 클러스터의 메모리를 활용하여 대규모 데이터를 저장하고 캐싱한다.
IMDG는 다음과 같은 특징을 갖는다.
- 대용량 메모리 풀: IMDG를 사용하면 여러 대의 서버를 연결하여 대용량의 메모리 풀을 형성할 수 있다. 이러한 메모리 풀은 데이터의 빠른 접근과 처리를 가능케 한다.
- 데이터 적재 및 캐싱: IMDG는 대용량 데이터를 메모리에 적재하거나 캐싱하여 빠른 응답 시간을 제공한다. 이를 통해 데이터에 대한 실시간 접근 및 처리가 가능해진다.
- IMDB 기능: IMDG는 In-Memory Database (IMDB)의 기능을 포함하고 있다. 이는 데이터를 메모리에 저장하고 관리하는 데이터베이스 기능을 제공하여 더 빠른 데이터 액세스 및 처리를 가능하게 한다.
- 디스크 기반 데이터 캐싱: IMDG는 디스크 기반의 이기종 데이터베이스에 이미 저장된 데이터를 메모리에 캐싱함으로써, 기존 시스템을 유지하면서도 더 빠른 데이터 처리를 제공할 수 있다. 이는 기존 시스템의 성능을 향상시키는 데 도움이 된다.
따라서 IMDG는 대규모 데이터 처리를 위한 고성능 및 확장 가능한 솔루션을 제공하며, 메모리를 활용하여 빠른 데이터 액세스 및 처리를 가능케 합니다.
Hazelcast 아키텍처
- Hazelcast 클러스터 구성:
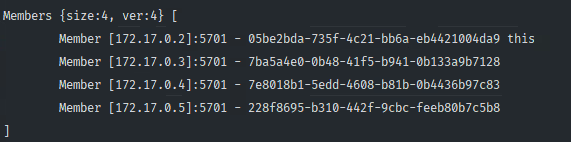
- 각 서버에는 Hazelcast Member라는 Java 프로세스가 실행되며, 이러한 Member들이 네트워크를 통해 서로 연결되어 클러스터를 형성한다.
- Disk 기반 데이터 캐싱:
- Hazelcast는 다양한 디스크 기반 데이터베이스(RDBMS, MongoDB 등)와 연동되어 기존에 저장된 대용량 데이터를 메모리에 캐싱할 수 있다.
- 이를 통해 디스크에서 메모리로 데이터를 로드하고 캐싱함으로써 빠른 응답 시간과 성능 향상을 제공한다.
- 분산된 데이터 그리드:
- Hazelcast는 데이터를 메모리에 분산하여 저장하므로, 데이터에 대한 빠른 액세스와 처리가 가능하다.
- 데이터의 복제 및 분산 저장을 통해 고가용성과 장애 내성을 제공한다.
Hazelcast 설정
- gradle dependency 추가
// hazelcast
implementation 'com.hazelcast:hazelcast:4.0.2'
- Hazelcast instance 설정
<?xml version="1.0" encoding="UTF-8"?>
<hazelcast xmlns="http://www.hazelcast.com/schema/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.hazelcast.com/schema/config
http://www.hazelcast.com/schema/config/hazelcast-config-4.0.xsd">
<network>
<!-- <port auto-increment="true" port-count="20">5701</port>-->
<join>
<multicast enabled="true"/>
</join>
</network>
<map name="assets_device">
<time-to-live-seconds>120</time-to-live-seconds>
<eviction size="1000" max-size-policy="USED_HEAP_PERCENTAGE" eviction-policy="LRU"/>
</map>
</hazelcast>
Hazelcast DataType
- IMap
- MultiMap
Reference
- https://docs.hazelcast.com/imdg/latest/
- https://blog.microideation.com/2018/10/04/simple-two-node-hazelcast-cache-cluster-using-tcp-ip/
- https://www.baeldung.com/java-hazelcast
- https://www.javainuse.com/hazel/hazelcast_hello
- https://hazelcast.com/use-cases/hibernate-second-level-cache/
- https://brunch.co.kr/@springboot/56
- https://docs.spring.io/spring-framework/reference/integration/cache.html
- https://docs.hazelcast.org/docs/3.7/manual/html-single/index.html
- https://supawer0728.github.io/2018/03/11/hazelcast/
- https://wannaqueen.gitbook.io/spring5/spring-boot/undefined-1/40.
- https://www.tutorialspoint.com/hazelcast/hazelcast_serialization.htm
- https://github.com/MustafaOrkunAcar/hazelcast-code-samples