[C++] C++ 객체 지향부터 Modern C++ 까지 # day 2 template, lambda, auto type 추론, nullptr
template
일반화(generalization):
여러 상황에 적용할 수 있는 프로그램 하나를 만들 때 사용하는 방법
이러한 작업을 c++에서 템플릿 프로그래밍 또는 제네릭 프로그래밍이라고 부름
template: 일반화된 코드를 작성할 수 있도록 하는 기능
template의 필요성:
여러 상황에서 적용할 수 있는 하나의 프로그램을 만들 때 사용
템플릿은 다양한 자료형에 대해 코드 재사용성을 높이고 유연한 프로그래밍을 가능하게 한다.
template 사용법, 구문
template <typename T>
T add(T a, T b) {
return a + b;
}
class template
class template 은 자료형에 상관없이 사용할 수 있는 일반화된 클래스를 정의
class template 역시 class와 마찬가지로 interface와 구현이 있다.
class template의 interface와 구현 모두에 template 매개변수가 있어야한다.
template 인터페이스
template<typename T>
class Vector
{
private:
T data;
public:
Vector();
T get();
void set(T data);
};
template 구현
// get
template<typename T>
T Vector<T>::get() const
{
return data;
}
// set
template<typename T>
void Vector<T>::set(T d)
{
data = d;
}
template 인스턴스화
개별적인 자료형에 대한 함수 정의 생성이 컴파일 시점에 함수에 필요한 만큼 생성하는 과정
template 매개변수
타입(자료형) 매개변수: 일반적인 템플릿에서 가장 많이 사용하는 형태로, 데이터 타입을 매개변수로 받는 경우
비-타입(non-type) 매개변수: 자료형이 아닌 상수 값이나 포인터 같은 구체적인 값을 매개변수로 받는 경우
lambda
람다 함수
간결한 함수 객체를 생성하기 위한 도구로, 이름 없는 함수를 즉석에서 정의하고 사용할 수 있다.
함수 객체처럼 매개변수와 반환형을 정의할 수 있다.
std::find_if(container.begin(), container.end(),
[](int val) { return 0 < val && val < 10; });
클로저(closure)는 람다에 의해 만들어진 실행시점 객체
{
int x; // x는 지역 변수
...
auto c1 = // c1은 람다에 의해
[x](int y) { return x * y > 55; }; // 만들어진 클로저의
// 복사본
auto c2 = c1; // c2는 c1의 복사본
auto c3 = c2; // c3는 c2의 복사본
...
}
capture mode
C++에서 람다 함수가 외부 변수(즉, 람다 함수가 정의된 스코프 외부의 변수)에 접근할 수 있도록 하는 기능
기본적으로 람다 함수는 자신이 정의된 함수나 블록에서 선언된 변수를 직접 사용할 수 없지만, 캡처 리스트를 통해 이러한 변수에 접근할 수 있다.
람다 캡쳐 방식
값에 의한 캡처 ([=]): 외부 변수를 값으로 복사하여 람다 함수 내부에서 사용
참조에 의한 캡처 ([&]): 외부 변수를 참조로 가져와서 사용합니다. 원본 값을 변경할 수 있음
특정 변수만 캡처: 특정 변수만 값이나 참조로 캡처할 수 있습니다. 예를 들어 [x], [&x]와 같은 방식으로 사용
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
int multiplier = 3;
std::vector<int> numbers = {1, 2, 3, 4, 5};
// 값에 의한 캡처: multiplier의 복사본을 사용
std::for_each(numbers.begin(), numbers.end(), [=](int& n) {
n *= multiplier; // multiplier의 값은 캡처되었으므로 원본은 변경되지 않음
});
std::cout << "값에 의한 캡처 후: ";
for (const auto& num : numbers) {
std::cout << num << " "; // 출력: 3 6 9 12 15
}
std::cout << std::endl;
// 참조에 의한 캡처: multiplier에 직접 접근하여 수정 가능
std::for_each(numbers.begin(), numbers.end(), [&](int& n) {
multiplier += n; // 원본 multiplier 값이 변경됨
});
std::cout << "참조에 의한 캡처 후 multiplier 값: " << multiplier << std::endl; // 변경된 multiplier 값 출력
}
auto
명시적 타입 추론
변수의 자료형을 명시하여 코드의 가독성을 높이고, 타입을 명확하게 하는 것
auto type 추론
컴파일러가 초기화 값을 기반으로 자료형을 자동으로 추론 (복잡한 타입 추론을 컴파일러에게 위임)
auto 변수는 반드시 초기화해야 하며, 이식성 또는 효율성 문제를 유발할 수 있는 타입 불일치가 발생하는 경우가 거의 없음
긴 타입 이름을 줄일 수 있어 가독성을 높일 수 있으며, 타입 지정이 어려운 경우에 유용
auto는 중괄호 {}를 사용하면 **std::initializer_list**로 추론하는 특별한 규칙이 있음
// 명시적 타입 추론
std::map<std::string, std::vector<int>>::iterator it = myMap.begin();
// auto 사용
auto it = myMap.begin();
auto x1 = 27; // x1의 타입은 int
auto x2(27); // x2의 타입도 int
auto x3 = { 27 }; // x3의 타입은 std::initializer_list<int>
auto x4{ 27 }; // x4의 타입도 std::initializer_list<int>
auto, lambda, template 실습
배열, 리스트, 벡터
배열
메모리의 연속 공간에 채워져 있는 형태의 자료구조
인덱스를 사용하여 값에 바로 접근가능
새로운 값을 삽입하거나 특정 인덱스의 값을 삭제하기 어려움
배열의 크기를 선언시에 지정할 수 있으며 한번 선언할 경우 크기를 늘리거나 줄일 수 없다.
리스트
값과 포인터를 묶은 노드라는 것을 포인터로 연결한 자료구조
인덱스가 없으므로 접근하려면 head 포인터부터 순서대로 접근해야한다. 접근속도가 느리다.
포인터로 연결되어있어 데이터의 삽입과 삭제 연산이 빠르다.
선언할 때 크기를 별도로 지정하지 않아도 된다.
포인터를 저장할 공간이 별도로 필요하여 배열보다 구조가 복잡하다.
vector
c++ stl에 있는 자료구조 컨테이너 중 하나로 사용자가 손쉽게 사용하기 위해 정의한 클래스
기존의 배열과 같은 특징을 가지면서 배열의 단점을 보완한 동적배열의 형태
동적으로 원소를 추가 가능
맨마지막 위치에 데이터를 삽입하거나 삭제할 때는 문제가 없지만 중간 데이터의 삽입 삭제는 배열과 같은 매커니즘으로 동작한다.
배열과 마찬가지로 인덱스를 이용하여 각 데이터에 접근할 수 있다.
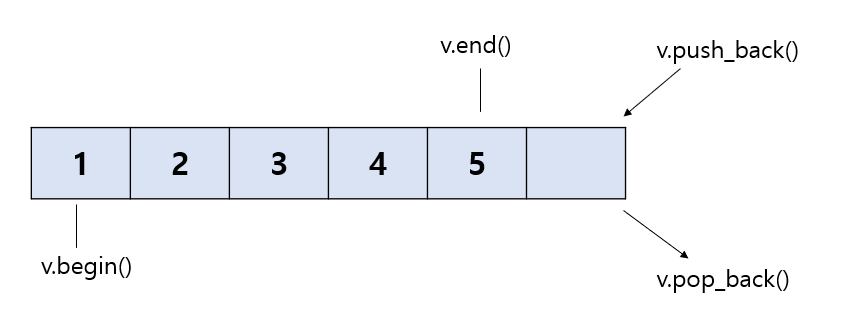
vector 사용법
// 선언
vector<int> A; // vector<자료형> 변수 이름; 형태로 선언
// 삽입 연산
A.push_back(1); // 마지막에 1 추가
A.insert(A.begin(), 7); // 맨 앞에 7 삽입
A.insert(A.begin()+2, 10); // index 2 위치에 10 삽입
// 값 변경
A[4] = -5; // index 4 위치의 값을 -5로 변경
// 삭제 연산
A.pop_back(); // 마지막 값 삭제
A.erase(A.begin()+3); // index 3에 해당하는 원소 삭제
A.clear(); // 모든 값 삭제
// 정보 가져오기
A.size(); // 데이터 개수
A.front(); // 처음 값
A.back(); // 마지막 값
A[3]; // index 3에 해당하는 값
A.at(5); // index 5에 해당하는 값
A.begin(); // 첫 번째 데이터의 iterator
A.end(); // 마지막 데이터의 iterator
iterator
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
vector<int> myVector = {10, 20, 30, 40, 50};
myVector.push_back(10);
myVector.push_back(20);
// iterator를 이용한 벡터 순회
for (vector<int>::iterator it = myVector.begin(); it != myVector.end(); ++it) {
cout << *it << " ";
}
cout << endl;
// auto 변수 사용
for (auto it = myVector.begin(); it != myVector.end(); ++it) {
cout << *it << " ";
}
cout << endl;
// lambda를 사용한 벡터 순회
for_each(myVector.begin(), myVector.end(), [](int value) {
cout << value << " ";
});
cout << endl;
// auto와 lambda를 함께 사용
for (auto it = myVector.begin(); it != myVector.end(); ++it) {
auto printElement = [](int value) {
cout << value << " ";
};
printElement(*it);
}
cout << endl;
return 0;
}
정렬
#include <iostream>
#include <vector>
#include <algorithm> // std::sort
int main() {
std::vector<int> myVector = {5, 2, 9, 1, 5, 6};
// 오름차순 정렬 (람다 사용)
std::sort(myVector.begin(), myVector.end(), [](int a, int b) {
return a < b; // a가 b보다 작으면 true, 오름차순
});
// 정렬된 벡터 출력
std::cout << "오름차순 정렬: ";
for (int num : myVector) {
std::cout << num << " ";
}
std::cout << std::endl;
// 내림차순 정렬 (람다 사용)
std::sort(myVector.begin(), myVector.end(), [](int a, int b) {
return a > b; // a가 b보다 크면 true, 내림차순
});
// 정렬된 벡터 출력
std::cout << "내림차순 정렬: ";
for (int num : myVector) {
std::cout << num << " ";
}
std::cout << std::endl;
return 0;
}
정렬 만들어 보기
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
int main() {
// 실수형 데이터
vector<double> data = { 1.203, 2.45, 9.54, 9.51, 5.43, 1.201, 6.43, 8.12, 3.11, 4.20 };
cout << "정렬 전 원 데이터(실수)" << endl;
print_all(data);
// 오름차순 정렬 (std::sort의 기본 동작)
sort(data.begin(), data.end());
cout << endl << "오름차순 정렬 결과" << endl;
print_all(data);
// 내림차순 정렬 (람다를 사용하여)
sort(data.begin(), data.end(), [](double a, double b) {
return a > b; // a가 b보다 크면 true (내림차순)
});
cout << endl << "내림차순 정렬 결과" << endl;
for (const auto& element : data) {
cout << element << " , ";
}
cout << endl;
return 0;
}
nullptr
0, NULL을 사용할 경우 문제점
0(int)과 NULL(정수 타입=>0으로 취급될 가능성) 을 사용할 경우 포인터를 기대하는 함수에서 의도치 않게 정수 오버로딩이 되는 문제가 발생할 수 있음
템플릿의 타입 추론시에도, 0과 NULL은 정수 타입으로 추론하는 반면, nullptr은 포인터 타입으로 추론함.
nullptr
명확한 포인터 타입이며, 모든 포인터 타입으로 암묵적으로 변환 가능. 따라서 코드의 명확성을 높이고 오버로딩 문제를 방지
nullptr을 사용하면 포인터와 관련된 코드가 훨씬 명확해지고, 의도하지 않은 정수 오버로딩 문제를 피할 수 있다.
특히 함수의 반환값이 포인터인지 정수인지 모호한 상황에서, nullptr을 사용하면 반환값이 포인터임을 명확하게 나타낼 수 있다.
template과 nullptr
템플릿 매개변수로 0이나 NULL을 전달하면 정수 타입으로 추론되지만, nullptr을 전달하면 포인터 타입으로 정확하게 추론된다.
// nullptr이 코드의 명확성을
// 높여주는 예제
auto result = findRecord( /* 인수들 */ );
if (result == 0) {
...
}
// findRecord의 반환 타입을 모르거나
// 쉽게 파악할 수 없다면, result가
// 포인터 타입인지 아니면 정수 타입인지를
// 명확히 말할 수 없게 된다.
// 반면 다음 코드에는 모호성(ambiguity)이
// 없다.
auto result = findRecord( /* 인수들 */ );
// 이 경우에는 result가 포인터 타입임이 분명해짐
if (result == nullptr) {
...
}
![[C++] C++ 객체 지향부터 Modern C++ 까지 # day 2 template, lambda, auto type 추론, nullptr](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FxO81O%2FbtsJQ4dKrMO%2Fx8kPcubK7SRsVAfR4AqTdk%2Fimg.png)